Plus longue sous-chaîne commune
Cet article est une ébauche concernant l’informatique.
Vous pouvez partager vos connaissances en l’améliorant (comment ?) selon les recommandations des projets correspondants.

Ne doit pas être confondu avec plus longue sous-séquence commune.
En informatique, le problème de la plus longue sous-chaîne commune, à ne pas confondre avec celui de la plus longue sous-séquence commune, consiste à déterminer la (ou les) plus longue(s) chaîne(s) consécutives de caractères qui est sous-chaîne de deux chaînes de caractères. Ce problème se généralise à la recherche de la plus longue sous-chaîne commune à plus de deux chaînes de caractères.
Exemple
La plus longue sous-chaîne commune à « ABABC », « BABCA » et « ABCBA » est la chaîne « ABC » de longueur 3. Les autres sous-chaînes communes telles que « AB », « BC » et « BA » sont plus courtes.
ABABC
|||
BABCA
|||
ABCBA
Formalisation du problème
Étant donné deux chaînes, de longueur et de longueur , trouver la plus longue chaîne étant en même temps sous-chaîne de et . Par définition la longueur de la plus longue sous-chaîne est comprise entre (vocabulaires disjoint) et ().







Algorithmes
Il est possible de déterminer la longueur et la position de départ de la plus longue sous-chaîne de et en à l'aide d'un arbre des suffixes généralisé (en). L'algorithme naïf faisant appel à la programmation dynamique est beaucoup plus coûteux en temps : .


Arbre des suffixes
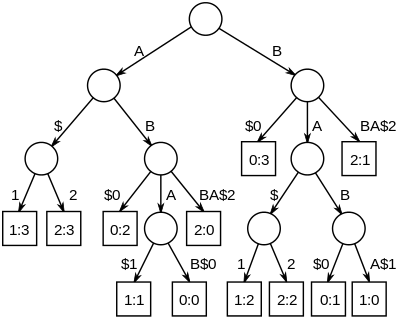
La plus longue chaîne commune à un ensemble de chaînes peut être déterminée en construisant l'arbre des suffixes généralisé puis en trouvant le nœud le plus profond ayant des feuilles pointant vers toutes les chaînes. Dans l'exemple ci-contre, le nœud auquel on arrive par « AB » a quatre feuilles dans son sous-arbre ; la feuille de gauche dit qu'une occurrence de la sous-chaîne « AB » commence en position 2 dans la chaîne 0 (« ABAB »), de même, la feuille de droite indique une occurrence débutant en position 0 dans la chaîne 2 (« ABBA ») ; des deux feuilles centrales, celle de gauche indique qu'une occurrence de la sous-chaîne « ABA » commence en position 1 dans la chaîne 1 (« BABA »).
La construction de l'arbre des suffixes a une complexité en temps de , où est la somme des longueur des chaînes représentées.


La recherche peut se faire en temps similaire grâce à des algorithmes de plus petit ancêtre commun[1].
Programmation dynamique
Dans un premier temps, on cherche le plus long suffixe commun pour chaque paire de préfixes des deux chaînes et . Le plus long suffixe commun du préfixe de longueur de et du préfixe de longueur de est
![{\displaystyle S[1,p]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/04884aeb2eb72ad338cec33d5abd97b177887a3a)

![{\displaystyle T[1,q]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/96caaf9409075d71e1b68bf4e8048cdbf72b2948)

![{\displaystyle {\mathsf {PLSuff}}(S[1,p],T[1,q])={\begin{cases}{\mathsf {PLSuff}}(S[1,p-1],T[1,q-1])+1&{\text{si }}S[p]=T[q]\\0&{\text{sinon}}.\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0a0bd4364328efbb60f721906aac7624d5c2f0c5)
Pour les chaînes « ABAB » et « BABA », on obtient:
A B A B 0 0 0 0 0 B 0 0 1 0 1 A 0 1 0 2 0 B 0 0 2 0 3 A 0 1 0 3 0
Le plus grand de ces suffixes communs à tous les préfixes est la plus longue sous-chaîne commune. Dans la table, elles sont indiquées en rouge, et dans l'exemple, les deux sous-chaînes communes de longueur maximale sont « ABA » et « BAB ».
![{\displaystyle {\mathsf {PLSC}}(S,T)=\max _{1\leq p\leq m \atop 1\leq q\leq n}{\mathsf {PLSuff}}(S[1,p],T[1,q]).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bd813a30f178c36ee9ae558aa5bd84b877a10e25)
La méthode peut être étendue à plus de deux chaînes en ajoutant des dimensions à la table.
Notes et références
Liens externes
Sur les autres projets Wikimedia :
- Plus longue sous-chaîne commune, sur Wikibooks
- Dictionary of Algorithms and Data Structures: longest common substring
- Perl/XS implementation of the dynamic programming algorithm
- Perl/XS implementation of the suffix tree algorithm
- Dynamic programming implementations in various languages on wikibooks
- working AS3 implementation of the dynamic programming algorithm
Source de la traduction
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Longest common substring problem » (voir la liste des auteurs).
Voir également
v · m Algorithmique du texte | |
|---|---|
| Recherche de sous-chaîne |
|
| Alignement de chaînes | |
| Mesure de similarité | |
| Arbre des suffixes | |
| Comparaisons |
|
 Portail de l’informatique
Portail de l’informatique








