ReLU
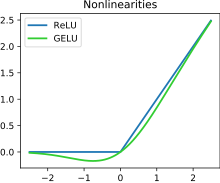
Reálná funkce jedné reálné proměnné zvaná ReLU (zkratka REctified Linear Unit)[1] nebo usměrňovač (rectifier) či rampa (ramp function) se používá především v kontextu umělých neuronových sítí jako aktivační funkce. Je definována jako kladná část svého argumentu:

kde x je vstup do neuronu. Její průběh popisuje také výstupní napětí ideálního usměrňovače v elektrotechnice v závislosti na vstupním napětí. Jako aktivační funkci ji zavedl Kunihiko Fukushima v roce 1969 v kontextu extrakce vizuálních prvků v hierarchických neuronových sítích.[2] Později se ukázalo, že má i biologickou motivaci a matematické odůvodnění.[3] V roce 2011 se zjistilo, že ReLU umožňuje lepší trénování hlubších sítí ve srovnání s předtím používanými aktivačními funkcemi, např. logistickou funkcí (která je inspirována teorií pravděpodobnosti; viz logistická regrese) nebo praktičtější hyperbolickou funkcí. ReLu a její varianty tak patří k nejoblíbenějším aktivačním funkcím pro hluboké učení a uplatňují se například v počítačovém vidění, rozpoznávání řeči[4] a výpočetní neurovědě.[5]
Výhody
- Řídká aktivace: Například v náhodně inicializované síti je aktivováno pouze asi 50 % skrytých jednotek (mají nenulový výstup).
- Lepší šíření gradientu: Méně problémů s mizejícím gradientem ve srovnání se sigmoidálními aktivačními funkcemi, které saturují v obou směrech.
- Efektivní výpočet: Pouze porovnávání, sčítání a násobení.
- Invariantní vůči měřítku: .

V roce 2011 se ukázalo, že použití ReLU jako nelinearity umožňuje trénovat hluboké neuronové sítě s učitelem bez nutnosti předtrénování bez učitele. ReLU ve srovnání se sigmoidou nebo podobnými aktivačními funkcemi umožňují rychlejší a efektivnější trénování hlubokých neuronových architektur na velkých a komplexních souborech dat.
Nevýhody
- Funkce ReLU není diferencovatelná v nule; je však diferencovatelná všude jinde a hodnota derivace v nule může být libovolně zvolena 0 nebo 1.
- Necentrovaná.
- Neohraničená.
- Neurony s ReLU mohou být někdy vytlačeny do stavů, ve kterých se stanou neaktivními v podstatě pro všechny vstupy (dying ReLU problem). V tomto stavu neprotékají neuronem zpět žádné gradienty, a tak neuron uvízne v trvale neaktivním stavu a „umírá“. Jde o variantu problému mizejícího gradientu. V některých případech může takto odumřít velké množství neuronů dané sítě, a to snižuje kapacitu modelu. Tento problém obvykle nastává, když je rychlost učení nastavena příliš vysoko. Může být zmírněn použitím tzv. netěsných (leaky) ReLU, které přiřazují malý kladný sklon pro x < 0; výkon sítě je však nižší.
Varianty
Po částech lineární varianty
Netěsné (leaky) ReLU
Netěsné ReLU mají malý kladný gradient, pro záporná čísla, tj. když neuron není aktivní.[4] To pomáhá zmírnit problém mizejícího gradientu. Například:

Parametrické ReLU
Parametrické ReLU (PReLU) posouvá tuto myšlenku dále tím, že převádí koeficient netěsnosti do parametru, který se učí spolu s dalšími parametry neuronové sítě.

Pro a ≤ 1 je to ekvivalentní s

a má tedy vztah k sítím typu „maxout“.
Nelineární varianty
Lineární jednotka s Gaussovou chybou (GELU)
GELU (Gaussian-error linear unit) je hladká aproximace ReLU:


kde je kumulativní distribuční funkce standardního normálního rozdělení.

Tato aktivační funkce je znázorněna na obrázku na začátku tohoto článku. Má „hrbol“ nalevo od x = 0 a slouží jako výchozí aktivace například pro model BERT .
SiLU
SiLU (sigmoid linear unit) nebo funkce swish je další hladká aproximace, poprvé uvedená v článku o GELU:


kde je sigmoida, logistická funkce.

Softplus
Další hladká aproximace ReLU je analytická funkce

která se nazývá funkce softplus nebo SmoothReLU. Pro velký záporný argument je to zhruba , takže malé kladné číslo, zatímco pro velké kladné je to zhruba , takže těsně nad .



Tuto funkci lze aproximovat jako
![{\displaystyle \ln \left(1+e^{x}\right)\approx {\begin{cases}\ln 2,&x=0,\\[6pt]{\frac {x}{1-e^{-x/\ln 2}}},&x\neq 0\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b2ee7d51d51afff7c0be67d189f28b50dc79be00)
To se substitucí dá převést na

![{\displaystyle \log _{2}(1+2^{y})\approx {\begin{cases}1,&y=0,\\[6pt]{\frac {y}{1-e^{-y}}},&y\neq 0.\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/24e5140ee98bf4c13e12e7d6083cbbe9fdb47041)
Sem lze přidat ještě parametr ostrosti :


Derivací softplus je logistická funkce.
Logistická sigmoidní funkce je hladkou aproximací derivace ReLU, Heavisideovy funkce.
Zobecnění softplus na více vstupních proměnných je LogSumExp s prvním argumentem nastaveným na nulu:

Funkce LogSumExp je

a jeho gradient je softmax; softmax s prvním argumentem nastaveným na nulu je vícerozměrné zobecnění logistické funkce. LogSumExp i softmax se používají ve strojovém učení.
ELU
ELU (Exponential Linear Units, exponenciální lineární jednotky) mají střední aktivaci bližší nule, což urychluje učení. Bylo prokázáno, že ELU mohou dosáhnout vyšší přesnost klasifikace než ReLU.

V těchto vzorcích je hyperparametr, který se ladí s omezující podmínkou .


Na ELU lze pohlížet jako na vyhlazenou verzi posunuté ReLU (SReLU), která má tvar se stejnou interpretací .

Mish
Funkci mish lze také použít jako hladkou aproximaci ReLU. Je definována jako

kde je hyperbolická tangenta a je funkce softplus.


Mish není monotónní a byla inspirována funkcí swish, což je varianta ReLU.[6]
Squareplus
Squareplus je funkce

kde je hyperparametr, který určuje rozsah zakřivené oblasti v blízkosti . (Například dává ReLU a dává funkci označovanou anglicky jako metallic means, kovové průměry.) Squareplus sdílí mnoho vlastností se softplus: Je monotónní, všude kladný, konverguje k 0 pro , konverguje k identitě pro a je hladký. Squareplus však lze vypočítat pouze pomocí algebraických funkcí, takže se dobře hodí pro situace, kde jsou omezené výpočetní zdroje nebo instrukční sady. Squareplus navíc nevyžaduje žádnou zvláštní pozornost k zajištění numerické stability, když je velké.







Reference
V tomto článku byl použit překlad textu z článku Rectifier (neural networks) na anglické Wikipedii.
- ↑ LIU, Danqing. A Practical Guide to ReLU [online]. 2017-11-30 [cit. 2024-03-26]. Dostupné online. (anglicky)
- ↑ Competition and cooperation in neural nets: proceedings of the U.S.-Japan joint seminar held at Kyoto, Japan, February 15-19, 1982. Příprava vydání Shun-Ichi Amari, M. A. Arbib. Berlin Heidelberg: Springer 441 s. (Lecture notes in biomathematics). ISBN 978-3-540-11574-8, ISBN 978-0-387-11574-0.
- ↑ HAHNLOSER, R. H.; SARPESHKAR, R.; MAHOWALD, M. A. Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit. Nature. 2000-06-22, roč. 405, čís. 6789, s. 947–951. PMID: 10879535. Dostupné online [cit. 2024-03-26]. ISSN 0028-0836. DOI 10.1038/35016072. PMID 10879535.
- ↑ a b Andrew L. Maas, Awni Y. Hannun, Andrew Y. Ng (2014). Rectifier Nonlinearities Improve Neural Network Acoustic Models.
- ↑ HANSEL, D.; VAN VREESWIJK, C. How noise contributes to contrast invariance of orientation tuning in cat visual cortex. The Journal of Neuroscience: The Official Journal of the Society for Neuroscience. 2002-06-15, roč. 22, čís. 12, s. 5118–5128. PMID: 12077207 PMCID: PMC6757721. Dostupné online [cit. 2024-03-26]. ISSN 1529-2401. DOI 10.1523/JNEUROSCI.22-12-05118.2002. PMID 12077207.
- ↑ SHAW, Sweta. Activation Functions Compared With Experiments. W&B [online]. 2020-05-10 [cit. 2024-03-26]. Dostupné online. (anglicky)
Portály: Matematika








